PlaidCTF 2023 Writeup
Finished as 103rd out of 622, with 3 flags and 301 points.
Writeup for PlaidCTF 2023 challenges:
Treasure Map (100 Points, 131 Solves)
The challenge page greets us with a picture of a map and an input where we can specify our course.
To see how our course is validated, we open up the sources. The ‘Check’ button calls check() on click.
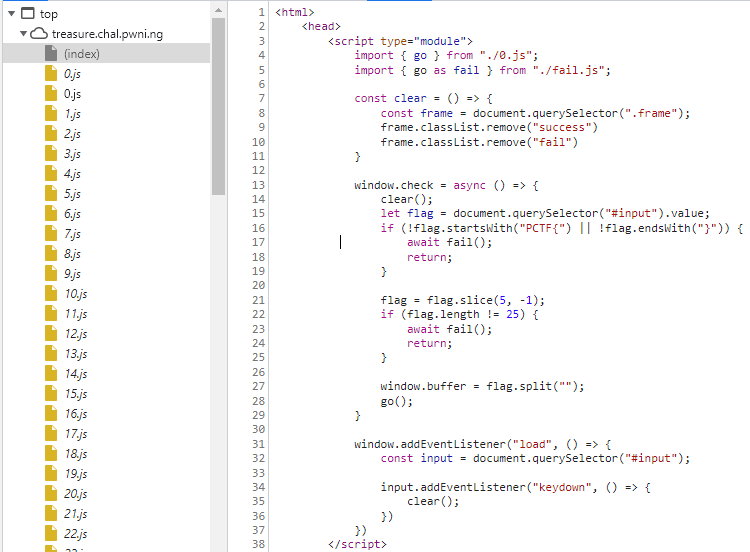
Before we even see the check() function, we find that there are tons of javascript files, starting from 0.js.
This goes up to 199.js, along with two more success.js and fail.js although not shown here in the picture.
success.js and fail.js just prints success or fail on the webpage respectively.
The check() function does the following:
- Validate that our input starts with
"PCTF{"and ends with"}" - Checks the string inside the curly braces has length 25, then stores this as a charArray in
window.buffer - Calls
go()function imported from./0.js
We can randomly keep a dummy course PCTF{1234567890123456789012345} in mind and continue.
Let’s take a look at the ./0.js file:

Here is a better look:
const b64 = `
A
B
...
=`;
export const go = async () => {
const bti = b64.trim().split("\n").reduce((acc, x, i) => (acc.set(x, i), acc), new Map());
const upc = window.buffer.shift();
const moi = await fetch(import.meta.url).then((x) => x.text())
const tg = await fetch(moi.slice(moi.lastIndexOf("=") + 1)).then((x) => x.json())
const fl = tg.mappings.split(";").flatMap((v, l) =>v.split(",").filter((x) => !!x).map((input) => input.split("").map((x) => bti.get(x)).reduce((acc, i) => (i & 32 ? [...acc.slice(0, -1), [...acc.slice(-1)[0], (i & 31)]] : [...acc.slice(0, -1), [[...acc.slice(-1)[0], i].reverse().reduce((acc, i) => (acc << 5) + i, 0)]].map((x) => typeof x === "number" ? x : x[0] & 0x1 ? (x[0] >>> 1) === 0 ? -0x80000000 : -(x[0] >>> 1) : (x[0] >>> 1)).concat([[]])), [[]]).slice(0, -1)).map(([c, s, ol, oc, n]) => [l,c,s??0,ol??0,oc??0,n??0]).reduce((acc, e, i) => [...acc, [l, e[1] + (acc[i - 1]?.[1]??0), ...e.slice(2)]], [])).reduce((acc, e, i) => [...acc, [...e.slice(0, 2), ...e.slice(2).map((x, c) => x + (acc[i - 1]?.[c + 2] ?? 0))]], []).map(([l, c, s, ol, oc, n], i, ls) => [tg.sources[s],moi.split("\n").slice(l, ls[i+1] ? ls[i+1]?.[0] + 1 : undefined).map((x, ix, nl) => ix === 0 ? l === ls[i+1]?.[0] ? x.slice(c, ls[i+1]?.[1]) : x.slice(c) : ix === nl.length - 1 ? x.slice(0, ls[i+1]?.[1]) : x).join("\n").trim()]).filter(([_, x]) => x === upc).map(([x]) => x)?.[0] ?? tg.sources.slice(-2, -1)[0];
import(`./${fl}`).then((x) => x.go());
}
//# sourceMappingURL=0.js.map
Let’s go through this line by line.
At the top of the file a const b64 = "A-Za-z0-9+/=" separated by newlines is declared.
Then in the first line of go(), const bti = b64... is defined, but hard to understand what it is yet.
Next, const upc is given the value window.buffer.shift(), which is our input.
This takes the next character from our input, which in our case would be '1'.
Onto const moi, import.meta.url is metadata that contains the url of the module, which is ./0.js in this case.
After fetching this module moi is given the text() of this file, so moi contains the whole javascript source code.
moi = "const b64 =... ... //#sourceMappingURL=0.js.map"
const tg takes the string after the last occurence of '=' of moi, which is 0.js.map.
It fetches the json stored in this file.
const fl does some really obfuscated calculation, extra points if you can understand what it does through static analysis.
Lastly, it imports and runs another go() function using const fl as the filename.
That is as far as I could go with my static analysis. Let’s find out more by dynamically analysing the code.
One great tip when solving reversing + web challenges is to make full use of the browser.
Let the javascript console of the browser to do the heavylifting.
Copy the source code in 0.js to our console, and we can view what the variables evaluate to.
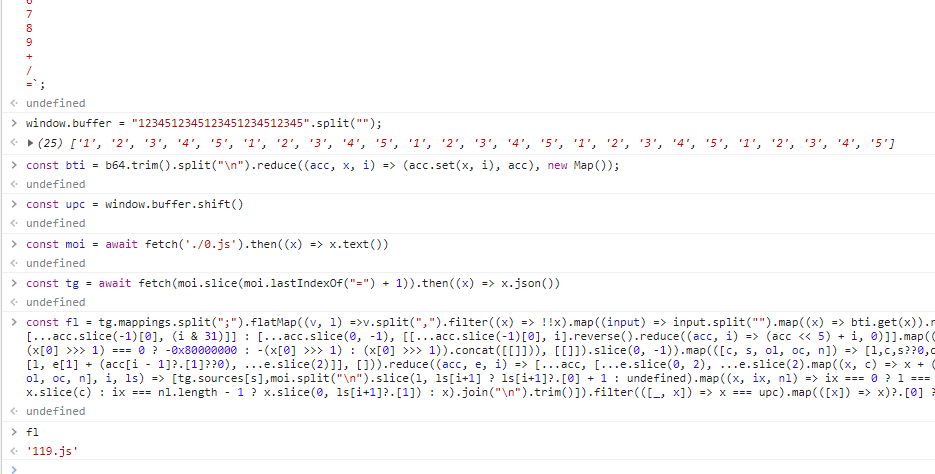
fl evaluates to 119.js, and we would call the go() function from there.
Viewing the other javascript files reveal that they are all exactly the same.
So from 119.js we would jump to another x.js file, and we would jump again… etc.
But fl must depend on our input somehow, otherwise it would always jump to 119.js which is uninteresting.
We search (ctrl+f) the string upc which is a fragment of our input that should affect the execution.
Surprisingly, it is only used once in the calculation of fl, at the very end in a filter.
const fl = (heavily obfuscated code).filter(([_, x]) => x === upc).map(([x]) => x)?.[0] ?? tg.sources.slice(-2, -1)[0];
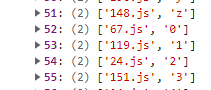
We can copy into our console the part before the filter to see what it is.

So fl before the filter is a map that associates the next file to jump to with a character.
Our suspicion is confirmed after seeing that 119.js is indeed the file to jump to given our input '1'.
Now, given that our input is exactly 25 characters long, we must reach success.js after exactly 25 jumps.
That means we can go backwards, and search which javascript files jump to success.js on what input character.
Then find which javascript files jump to that certain javascript file, and so on 25 times.
But with 200 javascript files, there could be around 200 ** 25 = 3.36e+57 possible paths, which is completely infeasible to search completely.
However, let’s just try anyway.
Here’s my code to find which files jumps to success.js.
for (let i = 0; i < 200; i++) {
let moi = await fetch(`./${i}.js`).then((x) => x.text())
let tg = await fetch(moi.slice(moi.lastIndexOf("=") + 1)).then((x) => x.json())
let fl = tg.mappings.split(";").flatMap((v, l) =>v.split(",").filter((x) => !!x).map((input) => input.split("").map((x) => bti.get(x)).reduce((acc, i) => (i & 32 ? [...acc.slice(0, -1), [...acc.slice(-1)[0], (i & 31)]] : [...acc.slice(0, -1), [[...acc.slice(-1)[0], i].reverse().reduce((acc, i) => (acc << 5) + i, 0)]].map((x) => typeof x === "number" ? x : x[0] & 0x1 ? (x[0] >>> 1) === 0 ? -0x80000000 : -(x[0] >>> 1) : (x[0] >>> 1)).concat([[]])), [[]]).slice(0, -1)).map(([c, s, ol, oc, n]) => [l,c,s??0,ol??0,oc??0,n??0]).reduce((acc, e, i) => [...acc, [l, e[1] + (acc[i - 1]?.[1]??0), ...e.slice(2)]], [])).reduce((acc, e, i) => [...acc, [...e.slice(0, 2), ...e.slice(2).map((x, c) => x + (acc[i - 1]?.[c + 2] ?? 0))]], []).map(([l, c, s, ol, oc, n], i, ls) => [tg.sources[s],moi.split("\n").slice(l, ls[i+1] ? ls[i+1]?.[0] + 1 : undefined).map((x, ix, nl) => ix === 0 ? l === ls[i+1]?.[0] ? x.slice(c, ls[i+1]?.[1]) : x.slice(c) : ix === nl.length - 1 ? x.slice(0, ls[i+1]?.[1]) : x).join("\n").trim()])
if (fl.filter(([x, _]) => x === 'success.js').length > 0) {
console.log(fl)
console.log(i)
console.log(fl.filter(([x, _]) => x === 'success.js'))
}
}
After running the code, we see that only one file has a path to success.js!
Only 41.js, when given the character '!', jumps to success.js.
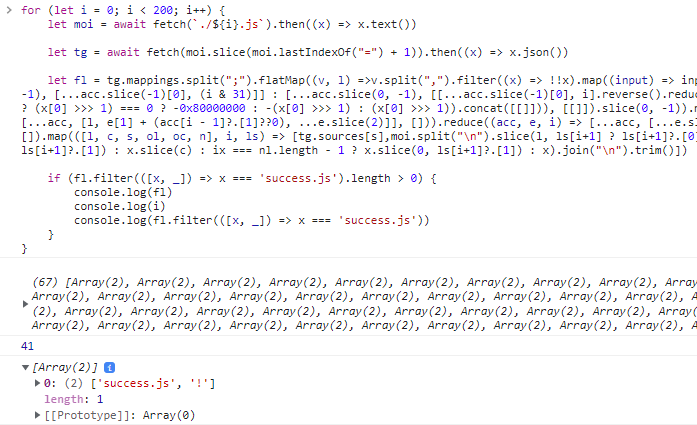
Thankfully, the path is quite straightforward and we can search it backwards easily.
We now know that the 25th character should be a '!'.
We repeat this 25 times, and get the sequence of characters Need+a+map/How+about+200!
We submit this as our course and we complete the challenge
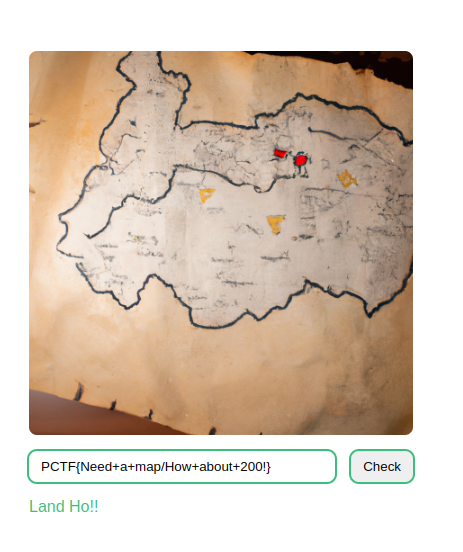
Flag: PCTF{Need+a+map/How+about+200!}
CSS (200 Points, 80 Solves)
The challenge page shows a Combination Lock that would give us our flag when solved.

The source of this webpage is plain HTML + inline CSS, with no javascript.
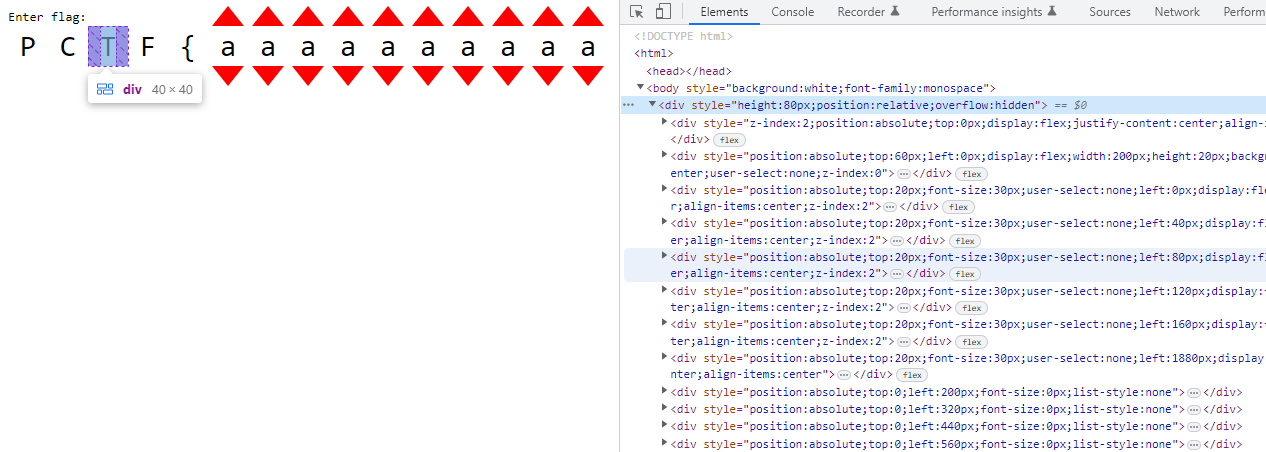
Clicking on the arrows changes the characters, and can range from a-z_.
Not knowing what to do, I just digged through the html file, and I found some interesting things about the layout of the page.
- The characters are grouped in threes, in a
div - There are 14 groups of these 3 character
divs. - Inside these parent
divs there is a nesteddivthat contains lots ofdetailshtml tags, and 4 extradivs. - The 4 extra
divs had their csstopproperty calculated in a weird obfuscated way, and they contained image data.
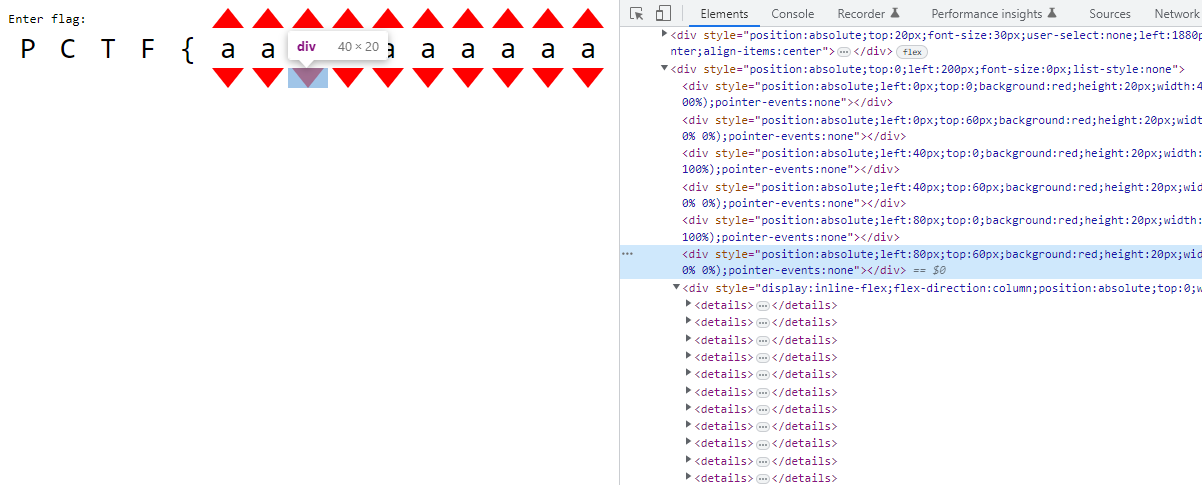
Aside from the 6 divs for each of the red arrows in the group, there is an extra div with many details html tags.
The details html tag is like a toggle bullet point that can open and close, showing or hiding contents, and which changes the amount of content/space taken up on the page.
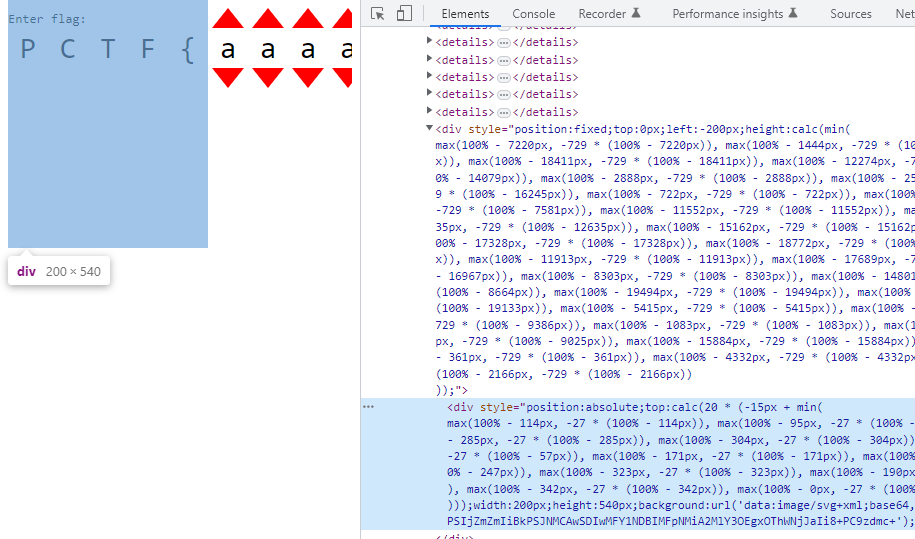
After 78 of these details tags, there are four divs with image data, with very weird css height and top properties.
The image data is stored as css background attribute,
background:url('data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyMDAiIGhlaWdodD0iNTQwIj48cGF0aCBmaWxsPSIjZmZmIiBkPSJNMCAwSDIwMFY1NDBIMFpNMiA2MlY3OEgxOThWNjJaIi8+PC9zdmc+');
After decoding this from base64, we find that it is a svg path element that can draw shapes.
➜ ~ echo "PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyMDAiIGhlaWdodD0iNTQwIj48cGF0aCBmaWxsPSIjZmZmIiBkPSJNMCAwSDIwMFY1NDBIMFpNMiA2MlY3OEgxOThWNjJaIi8+PC9zdmc+" | base64 -d
<svg xmlns="http://www.w3.org/2000/svg" width="200" height="540"><path fill="#fff" d="M0 0H200V540H0ZM2 62V78H198V62Z"/></svg>%
However, the color fill of the shapes is “#fff” (white) which means we cannot see any of them, since our webpage background is white as well.
Let’s change the background color to grey. We also need to remove the overflow: hidden css property from the top div to view the path elements.
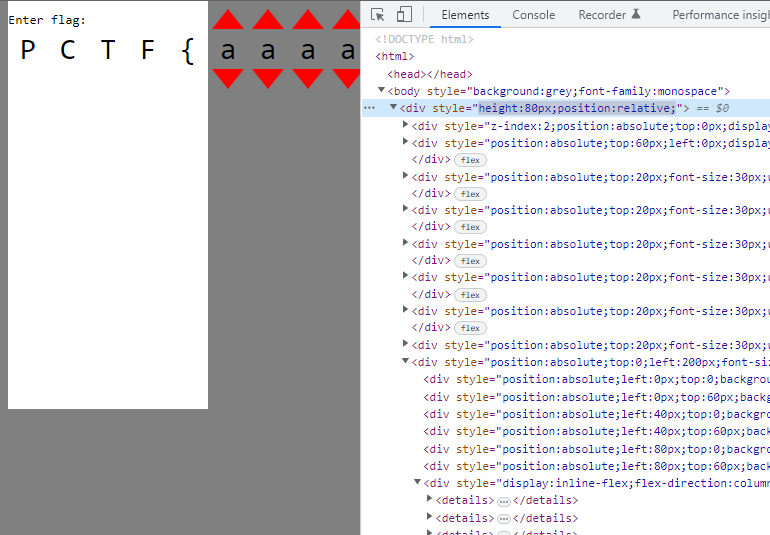
Since there are a lot of them stacked on top of each other (4 path elements from each 14 group div), lets pull one out and see how it looks.
I have modified the left css property to '200px' to pull it to the right.
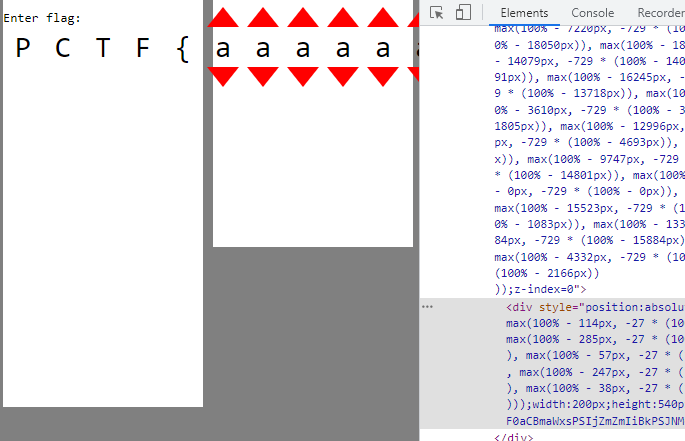
Although it might not seem like much, something interesting is revealed when we now change the combinations of characters.
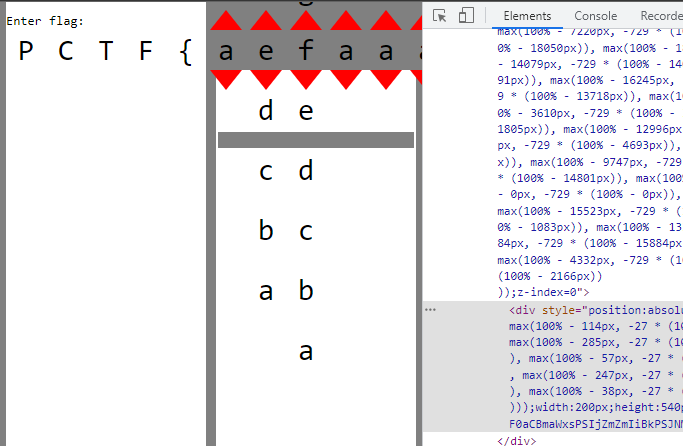
The path element moves down!
Changing the character combination moves the path elements vertically.
I believe this is because when the arrows are clicked, the <details> tag elements are opened, and more space is taken up. This pushes other content in the same div further down.
Wait, but why is there a bar missing in the path element?
If we look back at the source code more carefully, there is a sneaky div hidden behind everything, using css property z-index:0.
Let’s pull it to the front by increasing the z-index, to see what it is.

Aha! The correct text is hidden behind all of the path elements, and we have to change the character combinations until all of the transparent bars of each path element matches up with the text, showing the correct text!
And since the character combinations are grouped in threes, each of the 3 characters only affect their 4 path elements.
This means we can simply brute force 27 ** 3 = 19683 possible character combination in each group, and check if the 4 path elements line up with the correct text behind it.
To find out at which vertical position each of the path elements should be at, we can pull each of them out to the side, and alter the character combination until it lines up, then record their top css property.
We can do this using window.getComputedStyle(pathElement).top on the browser console.
Then, we can simply brute force the character combination so that every path element lines up and the final character combination should be our flag.
Here is my javascript code:
let tops = ['0px', '20px', '-380px', '-60px', '40px', '-20px', '-180px', '-80px', '-80px', '-80px', '-40px', '-60px', '-20px', '-240px', '-140px', '-100px', '-20px', '-20px', '-120px', '-160px', '-380px', '20px', '-20px', '-160px', '-200px', '-80px', '-60px', '-60px', '60px', '-140px', '-60px', '-240px', '60px', '-80px', '-180px', '-60px', '40px', '-60px', '-240px', '-60px', '-220px', '40px', '-260px', '0px', '-20px', '-60px', '-120px', '60px', '-240px', '40px', '-60px', '-20px', '40px', '-60px', '20px', '40px']
for (let n = 0; n < 14; n++) {
let grandparent = document.children.item(0).children.item(1).children.item(0)
let parent = grandparent.children.item(8 + n)
let details = parent.children.item(6)
let done = false
for (let i = 0; i < 26; i++) {
details.children.item(i).open = false
}
for (let i = 0; i < 27; i++) {
for (let j = 26; j < 52; j++) {
details.children.item(j).open = false
}
for (let j = 26; j < 53; j++) {
for (let k = 52; k < 78; k++) {
details.children.item(k).open = false
}
for (let k = 52; k < 79; k++) {
if (window.getComputedStyle(details.children.item(78).children.item(0)).top == tops[n * 4 + 0] && window.getComputedStyle(details.children.item(79).children.item(0)).top == tops[n * 4 + 1] && window.getComputedStyle(details.children.item(80).children.item(0)).top == tops[n * 4 + 2] && window.getComputedStyle(details.children.item(81).children.item(0)).top == tops[n * 4 + 3]) {
done = true
break
}
if (k < 78) {
details.children.item(k).open = true
}
}
if (done) {
break
}
if (j < 52) {
details.children.item(j).open = true
}
}
if (done) {
break
}
if (i < 26) {
details.children.item(i).open = true
}
}
}
The tops array store the top value each path element should have to line up.
This does take around a minute to execute, but when completed the page should look like this:
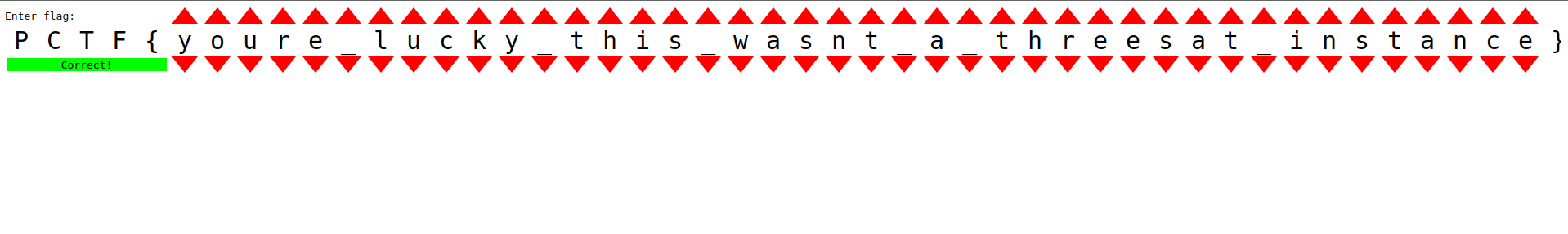
Flag: PCTF{youre_lucky_this_wasnt_a_threesat_instance}